
WoW Classic: Ein Blogeintrag zu den technischen Herausforderungen des AQ-Events

Gestern Abend veröffentlichte das Entwicklerteam von World of Warcraft einen neuen Blogeintrag auf ihrer offiziellen Communityseite, der den Fans von WoW Classic näher bringen sollte, wie viel Arbeit eigentlich in die vor Kurzem durchgeführte Rückkehr des klassischen AQ-Events geflossen ist. Während die Beiträge dieser Art sich in der Vergangenheit oft um das Design oder das Balancing der Inhalte von WoW drehten, so stellt dieser neue Beitrag interessanterweise aber die technische Seite der Entwicklung in den Vordergrund. Deshalb geht dieser informative Blogeintrag auch unter anderem darauf ein, welche technischen Herausforderungen das Team bewältigen musste, welche Ziele sie verfolgten, wie sie einen wesentlich flüssigeren Ablauf des Events gewährleisten konnten, welche Maßnahmen im Kampf gegen nervige Lags eingeleitet wurden und welche Verbesserungen das Event aus WoW Classic von dem Vanilla-Event unterscheiden.
Dieser neue Beitrag der Mitarbeiter von Blizzard Entertainment stellt einen durchaus gelungenen Artikel dar, der auf überraschend viele Punkte eingeht, die normalerweise von den Spielern ignoriert werden und trotz der harten Arbeit der Entwickler auf wenig Anerkennung stoßen. Schließlich macht sich ein Spieler von World of Warcraft nicht wirklich Gedanken um die technische Seite des Spiels, wenn alles problemfrei abläuft und es zu keinen größeren Ausfällen oder enormen Lags kommt. Natürlich wird solch ein Zustand aber nur dadurch gewährleistet, dass die Entwickler viel Arbeit und Zeit investieren und dauerhaft Verbesserungen in das Spiel einbauen. Wer sich also für die technische Seite der Entwicklung interessiert oder einfach nur einen Blick hinter die Kulissen werfen möchte, der sollte sich den folgenden Beitrag auf jeden Fall durchlesen. Leider gibt es bisher nur eine englische Variante dieses Artikels.
Engineer’s Workshop: Recreating the Ahn’Qiraj War Effort
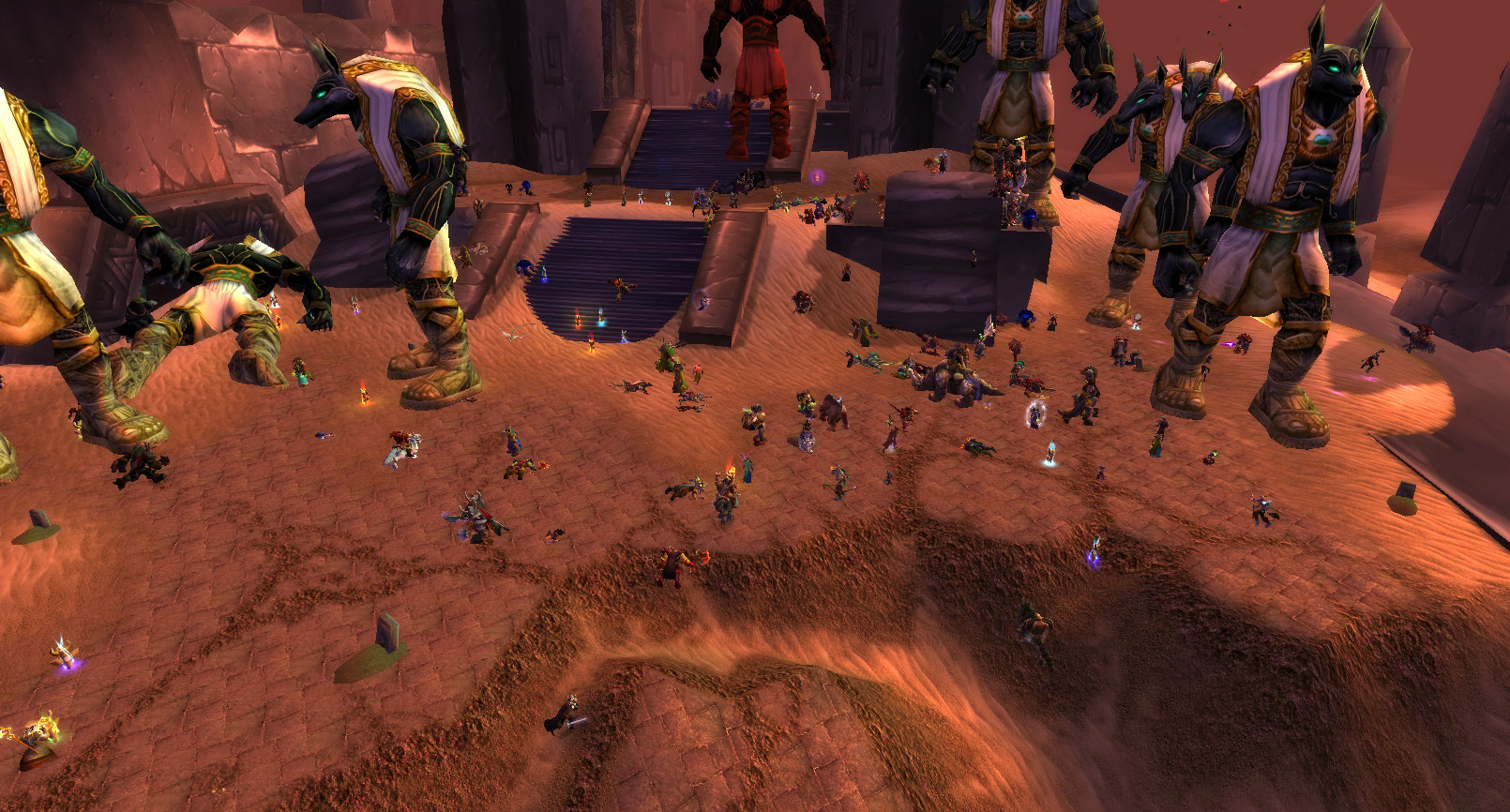
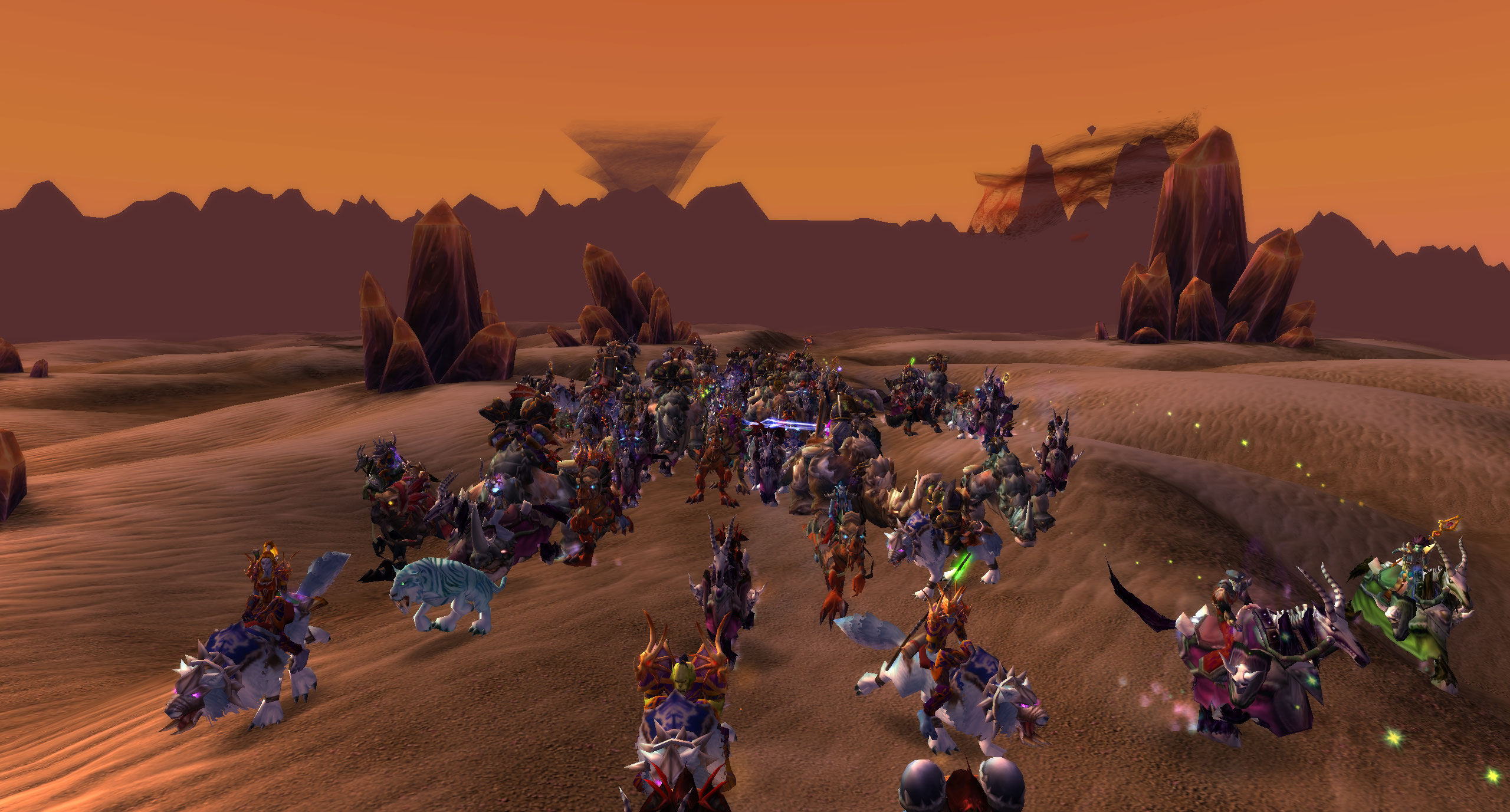
War is upon us. Earlier this month, one of the most anticipated events of World of Warcraft: Classic went live—the Ahn’Qiraj war effort. Entire Classic realms—the might of the Horde and Alliance combined—came together, contributing resources to open the gates and unlock the Ahn’Qiraj raids. When the War of the Shifting Sands took place the first (and only) time in 2006, thousands of players from each realm flew or hoofed it over to Silithus to partake in or witness the chaos. The turnout was beyond the development team’s wildest imaginings and, simply put, we were not prepared. Servers quickly become overloaded, and many players were caught in a loop of logging in, disconnecting, and trying to get back online over a 12-hour period while our engineers scrambled to hotfix issues and get players reconnected. While we did manage to stabilize servers during the event, and learned quite a few lessons, we saw opportunities to do better. Fifteen years later, we were ready to recreate one of the most epic moments in WoW history for WoW Classic by focusing on server optimization to combat lag and eliminate server crashes, all while hosting up to twice as many players in Silithus than we did during the event’s debut in 2006.
In this article, we’ll walk you through how we were able to recreate this highly anticipated event by going over how we use automated players and stress tests to determine breakpoints and handcraft optimization solutions, how we came up with solutions in the software to solve problems that hardware couldn’t, and how we curated a global event with limited server crashes, all while preserving the WoW Classic gameplay experience.
Recreating the War of the Shifting Sands
We had three specific goals in mind when approaching how we would need to engineer this event: Prevent chain crashes, increase the expected zone player limits, and determine how much lag was tolerable before porting players outside of Silithus. Before we can get into the nuts and bolts of how we maximized server performance, it’s important to understand the constraints we’re working in: the limitations of WoW Classic’s codebase, how population management solutions work, and how they affect gameplay.
Beyond Boundaries
The modern version of World of Warcraft was built upon the foundation of the original codebase released 15 years ago. Since the game’s launch, we’ve developed more modern ways to handle high player counts within Battle for Azeroth, most notably sharding. Shards allow WoW servers to host many more players in-game than we were capable of in 2006. In Battle for Azeroth, we use them to manage servers’ player load by making a copy of a zone (e.g. Zuldazar) once the player count reaches a certain threshold. This neutralizes lag issues by spreading players across different versions of the zone, since player interactions are among the most CPU intensive due to the amount of packets that they constantly send to the server for pinpoint accuracy on their movements and spells casts. Additionally, sharding mitigates potential lag issues that can be encountered when transitioning into a new zone where the player count goes over the threshold. Sounds simple enough, except there’s a catch—WoW Classic has been engineered to be a faithful recreation of the original 1.12 game data, which includes preserving its gameplay quirks. In rare cases, shards will cause your quarry, such as an enemy player or NPC, to disappear when phasing into a new zone. Keeping shards in would mean losing some of those nostalgic gameplay moments of chasing players and NPCs across zone boundaries. So, now we needed to come up with a solution that didn’t interfere with the original gameplay while also allowing us to get more players onto the server without forcing players to suffer through unplayable lag.
To handle this issue, we elected to use layers—copies of entire regions (e.g. Eastern Kingdoms)—to manage player population and lag issues while keeping the memorable charm of the original release intact so players could once again kite world bosses across zones and chase enemy players across borders within a region without the risk of them being reassigned to a different shard. However, layers were designed as a non-permanent solution. Because the original 1.12 release did not use either sharding or layering technologies, we promised players that we would only use layers at the launch of WoW Classic and phase them out over time as they dispersed more evenly throughout the world. There are a few cases in which we still use layering due to incredibly high populations of active players (e.g. North America’s Faerlina), but we have reduced the number of layers active on these realms since the game’s release. With 15 years of buildup, the AQ war is among the most highly anticipated events of WoW Classic, and we expect it to have the most amount of players in one area, outside of starting areas at the game’s release, without layers to manage it. Without layers or sharding population tech, we had to get creative, and quickly.

Handcrafting an Unforgettable Experience
We started the undertaking of finding a non-layer and shard population solution by generating headless clients—automated players—and instructing them to mimic what real players might do, such as casting spells, fighting NPCs, and moving around the area. This allowed us to take a snapshot of what performance could look like with thousands of players interacting in a single zone. After running these simulations, we then organized stress tests with volunteers so we could capture realistic player behavior and see how they compared. This gave us an indication of certain breakpoints and which pieces of our server’s code were experiencing the most issues at high player counts. Server frame time measurements were heavily scrutinized to see how close they were to causing a server to become unresponsive, also known as deadlocking.
The next step was to analyze what was affecting server performance so we could begin breaking down this monumental task into comprehensible goals. What we faced is a polynomial problem, which means we can’t solve it by throwing faster hardware at it because hardware’s not exponentially better. Instead, we have to handcraft the optimization by deliberately choosing which data should be communicated to players and how often. To illustrate this conundrum, let’s say we have 20 players jumping in a circle. The server relays the actions of each player to the other 19 through packets (data deliverables). In this group of 20, the server processes 380 packets (20 total players * 19 recipients = 380 packets). This issue compounds when more players do the same action in the zone. If we increase our example to 500 players, then 249,500 packets are sent from the server. If we increase our example again to 1,500 players then 2,248,500 packets are sent to the server. Depending on player actions, multiple packets are sent per second—keep in mind the above examples only account for one action. The more packets sent to the server increases the processing time the server must take on a single player while then going on to handle every other players’ actions. When this problem compounds, the servers begin to approach deadlocking. In WoW Classic, we have significantly more players per realm than realms did back in 2006, so the expectation is that we accommodate more players around the gates than we ever did before.
Optimizing Server Performance
Our servers are engineered to crash and restart if they encounter a deadlock, so we knew it was critical to do everything in our power to help minimize processing time. After some testing, it became clear that movement was the first piece of processing power that was putting heavy stress on our servers. We began by dropping facing updates (displaying the direction a character model is facing) and only send out player updates whenever a player starts, stops, or uses keyboard movement. Since latency with an excessive amount of players is already compromised, spending CPU time sending minor facing updates made the fidelity worse. As such, it was better to stop sending them. We made the decision to cull how often we sent movement updates in favor of having more players in a zone. Keep in mind we’re trying to find the breaking point before the servers fall over while allowing as many players into Silithus as possible. After all, it’s better to miss some movement updates than to not be able to login to your character at all. We also started throttling data that was marked as lower priority. Doing something that is deemed a “less important” action should not be sent with the same rate as “more important” actions. We saw many messages all being sent at once regardless of how important they were and optimized the code to only send you less important information in batches and less frequently.
Buffs and debuffs were another large hit on our performance. Throughout the world, especially when fighting mobs, buffs and debuffs are applied to units all the time. Though this may not seem like a big deal, with a high concentration of players all around each other, this information needs to be passed around. Similar to throttling low priority data, we now batch the buffs and debuffs to avoid sending multiple packets in succession to players.
Managing Player Populations
Aside from optimizing the servers to handle more players in each zone, it didn’t escape us that it’d be impossible to fit an entire realm’s population, (more than double what the original 1.12 WoW realm could handle) all within Silithus. Hard decisions had to be made to limit access into the zone by controlling who we allowed in and how many players we could allow in. We decided that we would only allow level 60 characters inside Silithus and would stop allowing eligible characters inside if was full. Creating this restriction was the right choice to make since the event in Silithus is known to be end-game content, and lower-level characters can still participate in the war effort in other zones, such as slaying the anubisaths that roam in The Barrens intended for level 20 to level 30 players. The second sticking point was that we knew the upper bound for how many players in an area we could handle without crashing the server; the question then became what that number should be reduced to for the best performance to player ratio. Over testing, we found this number to be around 1,500 players if they were stacked on top of each other. However, since the even takes over the whole zone, we saw minimal performance problems once players spread out.
The event was planned to take place in all regions, so we had to make sure this event worked across multiple layers. This means that a Scepter-bearer who rung the gong on one layer should begin the event across all other layers connected to that realm. Since the trigger for the event was based on a player interaction, we wanted to ensure the Scepter-bearer was visible across multiple layers so all players on the same realm could see them. This created an interesting problem since servers now had to relay this information that they typically wouldn’t need to communicate to each other. This can create a lot of complications as we compile and send updates through the servers to make sure we mirror the data across multiple layers, potentially to thousands of players.
We began developing this tech with the introduction of the Stranglethorn Fishing Tournament and applied it to the Onyxia, Nefarian, Zul’garub, and Rend world buffs later. Once we felt it worked as intended, we were ready to test it along with our other tech for the AQ war event.
Experimenting with Solutions
Now that we had addressed major tech hurdles and implemented several ways to optimize server performance, it was time to test everything we had worked on. We created a shortened version of the 10-hour war, scaled down to only run for an hour.
During the first stress test, we let nearly all players into the zone to see what would happen. At one point, we were nearly at 150% the capacity of an entire 1.12 realm. This was when we saw our test realm crash. We knew we had put a very high number on how many people we’d cap the zone to, and we were seeing numbers that had exceeded that number greatly. We investigated the issue and realized that the code allowing players to transfer both into a zone and out of zone was a queue that didn’t process many players at once. This was why players weren’t being ported out and why players were stuck on flight paths for an unusually long time. We restored the server and continued the stress test, adjusting as we went. We slowly lowered the number to a point where we felt it was still laggy, somewhat playable, and retained a much higher number of players than any zone had seen before. The event that was supposed to only take an hour and a half ended up taking up to four hours to complete because of crashes.
The second stress test was performed a week later. This allowed us to see if our optimizations worked. Upon loading into the stress test, we immediately noticed improvements—players were no longer stuck on flight paths leading into Silithus! We were able to obtain enough data that demonstrated how many players we could comfortably have in Silithus. After both tests, we moved forward with numbers that we felt accounted for the best balance between managing lag and server stability. These tests allowed us to see if our optimizations worked, and consider both tests successful since they allowed us to identify zone caps and iterate on them.
Spreading Server Solutions Across Azeroth
Originally, the optimizations were planned to only be active for Silithus during the War of the Sands. After we determined they’d be safe to rollout globally, we applied them to the entire world in 1.13.5. Once the war effort started, players began turning in supplies and harvesting bug corpses en masse. We saw a massive spike of players not only in Silithus, but also in our capital cities and outside zones. These optimizations helped make these experiences more performant, allowing large-scale PvP battles to take place across Azeroth. Some players even went as far as spawning the world boss Thunderaan to help clear out the other faction from a Hive.
Even though the gate opening event hadn’t taken place yet, some servers were experiencing strange issues regarding their war effort not progressing. The rate at which some servers were completing their war effort was so fast that it would cause there to be a race condition in the logic of each turn-in that could prevent the five-day timer from starting. Since the chance of this edge case happening was so small, we were able to fix those servers manually and then address this issue for future realms completing their effort.
Once the war efforts had been completed and five days had passed to open the gates, we began monitoring the Chinese realms that were first to open in the world. The first server in China to have an active Gong was Ouro. As we monitored our layer populations, we saw that most players on each layer were in Silithus. The event going off across multiple maxed-out layers for several thousand players at once was something we’d never done before. Though there was apparent lag, our servers didn’t experience any crashes during the first set of China realms opening.
Bang a Gong!
On August 4, it was noted that there would be several realms in North America ready to hit their gongs shortly after servers came up from reset. One by one, we actively monitored these realms on Game Master accounts and through our observation tools to monitor and address any issues that might be encountered. Each realm opened and began the event without issue. Scepter-bearers received their prestigious Black Qiraji Battle Tank mounts, players got to fight even bigger bugs, and we were pleased with the stability. As we were waiting for our first post-reset server to complete its five-day wait period, we noticed a significant issue: Events weren’t persisting after server restarts. This means that if a server would crash or restart, we would lose all progression in the event. Though this problem had existed since the beginning of WoW Classic’s development, there hadn’t been many applications of the use of events persisting across server restarts. Our team was able to address the problem quickly, but we needed to ensure that no further restarts could happen until we were able to deploy a fix and properly catalog all existing status of war efforts into our database without interruption to players.
Some may argue that allowing servers to crash is what made the original AQ war chaotic, which in turn made it memorable. Instead, we strove to cultivate that same fervor by curating a much more stable experience that could be shared with around 1,500 players in Silithus at the same time on each server. We wanted the memories of the Classic AQ war to be of having as many players as possible play through the 10-hour event without interruption. While we did experience a few realms crashing, we were able to get them back online quickly. These realms fully recovered and were back online within minutes and no subsequent crashes took place.
Over 4,000 players worldwide have become Scarab Lords, and that number continues to climb as each server progresses their war efforts. The excitement and engagement on Classic since the AQ war effort began has been incredible to watch and we’re grateful to all who joined us for the second War of the Shifting Sands!
































